Boring data science with kixi.stats
I'm pleased to announce that kixi.stats v0.5.0 has been released. Some of the new goodies are detailed below, but since it's early January 2019 (and close to the 3rd anniversary of the first commit), I can't help but reflect on the new features in the context of kixi.stats' evolution since its inception as well.
kixi.stats was originally concieved as a library of statistical reducing functions, which is to say functions which can be supplied to transduce. Accordingly, almost the entirety of kixi.stats.core is given over to reducing functions (each of which accepts elements from a sequence in turn and subsequently returns some derived value once the sequence is exhausted). Routines as trivial as calculating the min & max, to those which calculate descriptive statistics such as the standard-deviation or kurtosis, to those performing inferential hypothesis tests such as the z-test and chi-squared-test are all expressed as reducing functions.
In his discursive video What Clojure needs to grow, Eric Normand presents his view that frameworks tackling the more mundane aspects data science (and web development) are necessary for Clojure to reach a broader audience. In particular, he seeks more boring data science support. I'm not going to get into the framework vs library debate here, but for many reasons I detailed for InfoQ a while ago, I think that Clojure's natural strengths make it a great fit for doing daily data science.
It's in the area of statistical inference where recent kixi.stats work has been most focused. Boring data science sometimes means routine hypothesis testing on small datasets, and kixi.stats finally has t-test (implementing Welch's unequal variances t-test) and simple-t-test functions. In addition they—together with the z-test and chi-squared-test functions—all now return an implementation of the PTestResult protocol. This mandates implementations of p-value and significant? (with the option to override default one- or two-tailed test behaviour).
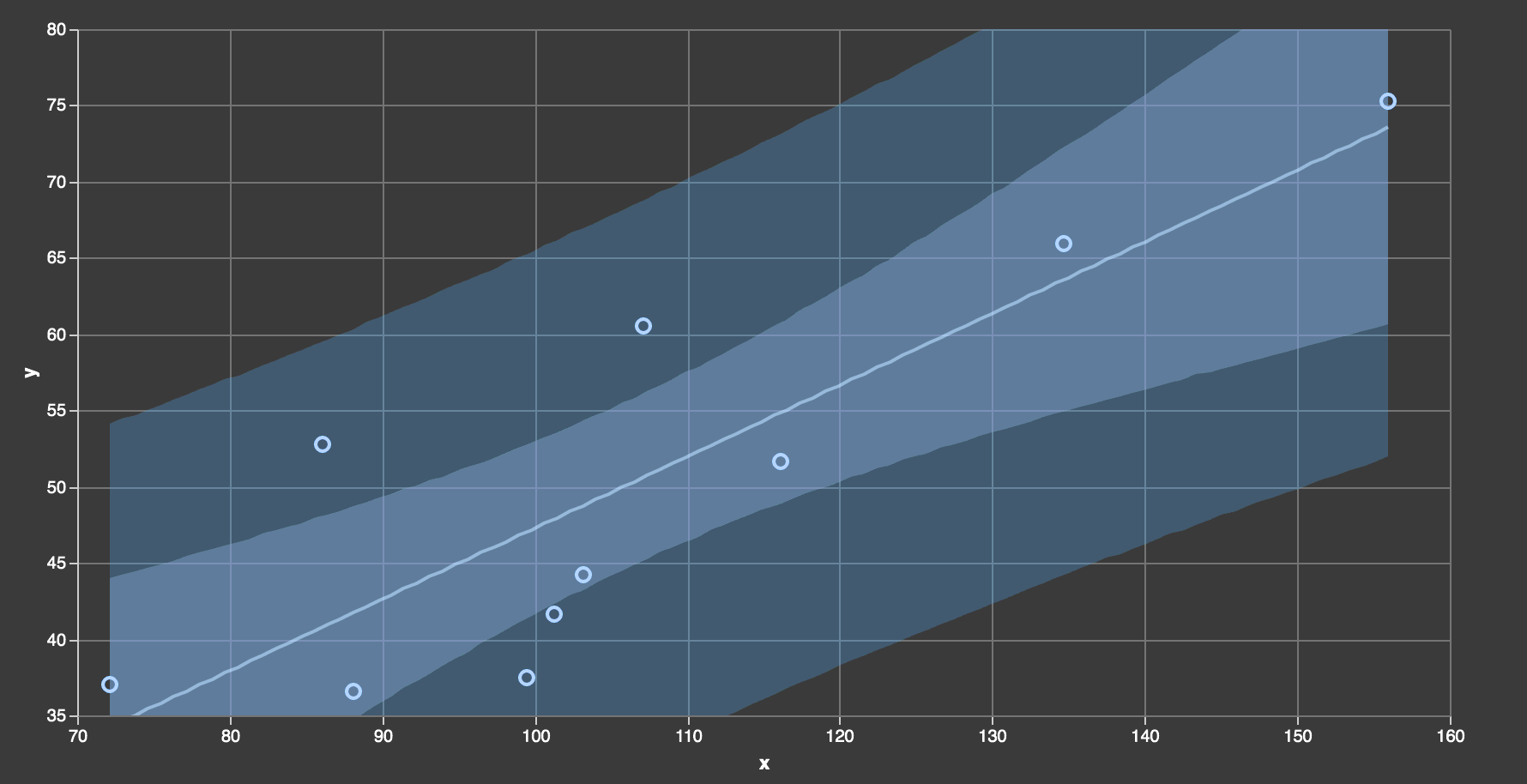
kixi.stats is now over 3 years old, and the self-imposed goal of meeting all challenges with a new reducing function has become a hinderance to further development. The library has grown to include 7 namespaces: core, digest, distribution, estimate, math, protocols, and test. The estimate namespace is new in the latest version. It contains a handful of functions, each of which accepts a sum-squares covariance digest and returns an estimate, e.g. of the line of best fit, regression or prediction interval at a given alpha value.
Hopefully the above serves to illustrate how kixi.stats has grown to include—in addition to simple descriptive scalar statistics—support for models, inference and more. I'm excited about each new release, and building confidence that there is room to complement the more specialist data science heavyweights such as the uncomplicate libraries or MXNet. I'm not ready to uninstall RStudio just yet, but the roadmap for the coming year should bring kixi.stats, and Clojure, some really boring new features.
Do you have an idea of what you'd like a boring data science framework to be? Email or Tweet me!
Henry Garner is the author of kixi.stats.